Incentivizing Machine Learning
prediction markets machine learning
With the introduction of chatGPT and image models such as stable diffusion, the immense usefulness of machine learning have started to really sink into public consciousness. Right now the power of these models lies in the hands of just a few actors. This is a big responsibility for them, and a significant risk for everyone who doesn’t share their values. The AI alignment problem is well known and there is no one solution. Distributing power to a wide set of actors that can mutually enforce checks and balances on each other is likely a big step in the right direction. Current efforts to decentralize machine learning include federated learning, sMPC, and zkML. While these are great innovations, we still lack a proper way to align incentives for actors involved. This article explore a cryptoeconomic incentive model that could align self-interested model operators with the values of a community.
Goals #
Let’s start by defining some goals for our system:
Community ownership - no one actor should be able to decide what the AI is being trained for. It should be trained according to the collective values and desires of a community.
Open competition - model creators should be able to freely compete to create the best model for the community and earn rewards.
On-chain minimization - training ML models is expensive and data intensive. A minimal amount of data and computation should happen on-chain. Both training and inference should happen off-chain whenever possible.
Individual privacy - participants who’s data is being used to train should retain as much privacy as possible.
Building blocks #
Let’s have a look at the core building blocks that would be needed to design a cryptoeconomic model for achieving these goals.
ZK inference #
Machine learning consists of two main parts: (1) training, which involves taking a look at a lot of examples to produce a model. This step requires a lot of data and computation. (2) inference, where a trained model is given some input and asked to produce some output. This step is cheaper and we can actually produce a zero knowledge proof for it. EZKL is a program that can produce these kinds of proofs for standard model files already. These sort of proofs are important because they allow an outside observer to trustlessly verify that a prediction was made by a given model. More precisely, given the hash of the model parameters and architecture, a third party can be sent input data and they can send back the resulting prediction along with a proof that the result was produced by the model with the given hash.
Prediction market #
Both prediction markets (PMs) and ML models try to make predictions about the world. ML models use historical data to make predictions about the future while PMs retroactively reward participants that accurately predicted about the future when the given fact is known. Generally PMs have been used as a tool to crowd source information about future events, or as a way to gamble. However, since ML models and PMs have very complimentary approaches to the same problem, it’s not difficult to see how PMs could be used as and incentive model for machine learning. If instead of individuals participating in the market, model operators can train models based on past data to accurately predict the outcome of the market, then use their models to trade. For this to work, two things are required; (1) the PMs can not be one of, there needs to be an iterated game so that models can learn and adapt, and (2) the PMs need to be fairly resolved based on the preferences of the community.
Self-certifying data #
By adding user-generated authority to data, any outside observer can verify that the data comes from the source it is claiming to come from. For example, in Ceramic all data is created as events which are signed with keys that are cryptographically tied to Ethereum accounts (or other blockchain accounts). This level of authenticity is important if we want to move towards better authenticity in ML models and cryptoeconomic games. If we have self-certifying data it is trivial to select a subset of accounts that can be used to resolve a prediction market fairly.
Iterated prediction game #
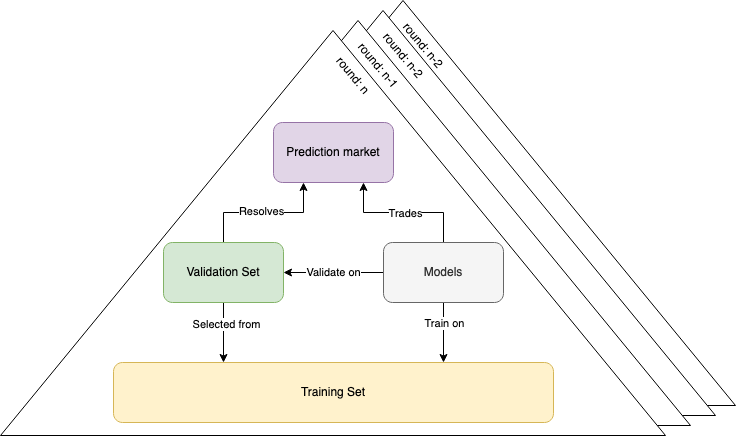
By combining the building blocks above we can create an iterated prediction game that lets a community incentivize model operators to train models based on an actively changing set of data. This data set can be seen as a data exhaust of the community and could be both active or passively collected. In addition, the community also defines a reward function that given a set of data can settle a prediction market. At a high level the system works like this:
- Start a prediction market for the validation set of
round n - Community starts generating the validation set for
round n - Model operators train their models using the reward function over the training and validation sets from
round < n - Model operators use their models to trade in
round n, every trade must include the hash of the model used - When
round nis over:round n+1is started (from step 1)- The prediction market on
round nis settled based on the reward function computed over the newly generated validation set ofround n
Generating data sets #
Both the training set and validation set should be generated continuously by the community. For example, this could be interactions on a social media platform, governance forum, or commerce platform. By default these actions would be stored encrypted on Ceramic data streams. The data is straight forward to query given the community is defined as a DAO or holders of a particular token (e.g. ERC20 or NFT collection). Most of this recorded data would act as the training set. The validation set needs to be public (at least initially, see improvements section). To generate the validation set a subset of the community is elected, randomly or through some other mechanism. At the end of every round the selected community subset will need to publicly publish their data points so that the prediction market can be resolved. Note that since the encrypted data was published on Ceramic, there is no way for the community subset to arbitrarily change their data to sway the PM without being detected.
Funding the prediction markets #
The prediction markets have a cost associated with them. By default no actor would trade in these markets if there was no counterparty. Every round the prediction market must be given some amount of funding so that model creators can participate in trading by making accurate predictions. The source of funding is out of scope for this article, but the PMs need to be funded by the community to be neutral. On-chain infrastructure like DAOs would likely make the most sense.
Inference as a service #
While the prediction market is useful to incentivize a model operators to train their models, using them for inference would be very inefficient and expensive. Imagine creating a prediction market for every social media post to detect if it is spam in order to hide it from users. Instead, why not just use the best performing models directly? Since model operators need to include the hash of their model when they trade in the PM we can actually ask the operator to do inference for us with this particular model and produce a zero-knowledge proof along with the result. This way we can be sure we are getting the result from the actual model they used when trading.
Training models #
Given that the data of the training set is encrypted, how would model operators actually train their models? Turns out that federated learning is a good approach to this problem.
Federated learning #
Instead of sending all data of all users to a centralized model operator that train a model, federated learning allows an operator to send the model out to data controllers, have them train the model and send back deltas of the model parameters. The model operator then has to aggregate these deltas into a complete updated model. Worth noting is that the model operators are not limited to the encrypted training set to create their models. They can use any data source that helps improve their models.
Central aggregators #
The easiest way to do the aggregation would be for a model operator to do this in a centralized manner. One of the advantages of this is that the model operator can pay the community members that sent back deltas that improved the model using micro payments. The main drawback is that community members privacy would be impacted since the operator could learn information about them from the model deltas they provide. This could be somewhat mitigated using differential privacy methods, but these only at a really large scale both in regards to the number of users and the number of data points needed per user.
Use cases #
The mechanism described above is very general and could be applied to a wide array of problems. Let’s briefly explore some specific examples to make things more concrete.
Spam detection in decentralized social networks #
Spam prevention is something that all social networks have to deal with. While it is fairly straight forward to prevent and automate in centralized social networks where the company behind the network can simply decide what’s spam and remove it. Doing so in decentralized networks is a known challenge. By using the mechanism above we can imagine a decentralized social network where any user can mark posts as spam. A spam prevention community would create the training and validation sets by reviewing posts marked as spam and publish this data encrypted to Ceramic. Users of the social network could opt-in to the spam prevention community and pay for their services. The community itself would use these payments to fund the iterated prediction game which would learn their spam prevention preferences over time. This would allow a relatively small community to prevent spam for a large number of users.
Predicting valuable data on Ceramic #
The Ceramic network currently uses a p2p architecture with no built in cryptoeconomic incentives. One way to reward nodes for making data available in the network could be using micropayments over state channels. While this mechanism gives nodes an incentive to store data preemptively, it is hard for a node to know if any given data stream will be retrieved a lot, or never retrieved. Each node could create their own ML model to make predictions, but using the iterated prediction game described above they could collaborate to create a shared more accurate model.
Improvements #
The description above provides a basic outline of how to incentivize the creation of gradually improving ML models. Many details are left out and there is much room for improvements. Below some improvements are discussed.
Distributed aggregation #
Instead of using a centralized aggregator sMPC and FHE can be used to aggregating deltas. These methods are topics of active research, but are also being used in practice to a smaller extent (e.g. in open mined and tensorflow encrypted). The main benefit of these methods is that privacy of community members would not be leaked to the model operator. A drawback of this is that rewarding members who’s deltas improve the overall models is not something that is currently feasible due to the large computational overhead.
Private validation set #
A flaw with the iterated prediction game defined above is that the validation set has to be public in order to resolve the PM. Ideally this data can be obfuscated in such a way that model operators doesn’t learn anything about the content of this data, but can still make definite predictions.
Conclusion #
What is presented above is a basic cryptoeconomic game that aligns the incentive of multiple model operators with a community that has a particular goal in mind. While there are many nuances to consider by implementors, such as privacy considerations and setting an appropriate reward functionthe iterated prediction game provides a scalable way to train machine learning models in a decentralized fashion. The core insight which enables this is that machine learning and prediction markets are two sides of the same coin. The former uses data from the past to draw conclusions, the latter retroactively rewards whoever made accurate conclusions about the future.
Thanks to Jonathan Passerat, Chhi’mèd Künzang and others participants of the 2022 Crypto, Security, AI Workshop put on by Forsight Insititue for a deep discussion on the topic, as well as Robert Drost for providing feedback on draft versions of this article.
- Next: Generative DID Maximalism
- Previous: An intro to complex adaptive systems